Summary
In this post, we look at how to read many similar files at once and combine them into a single dataset in R.
Suppose you have many similar files in .xlsx, .xls or .csv files with similar data, possibly in (almost) similar format, you definitely want to read all the files and combine the data in a single step instead of reading each file at a time. Scenarios in which this case of similar files may arise include, but are not limited to:
Survey data where you have multiple enumerators. In cases where the survey questions are similar and you are using tools such as ODK/Kobo, then the collected data looks the same just that you have different respondents/responses in different files from different enumerators.
Longitudinal data where the same data is collected periodically in the same format. A good example is daily share prices collected in .xlsx files such that at the end of the month you have 20+ files. Each file is named the date on which the share prices corresponds to e.g 12-04-2020.xlsx. Here is a screenshot of what the share prices may look like:

We will use the example of daily share prices to work through how to read multiple files and to combine them into a single dataset.
Step 1: Gather the data into one folder
It would be sensible, at the onset of data collection, to ensure all daily share prices files are placed within the same folder. Just in case this is not the case, gather all the files into one folder named daily_files within a parent folder called nse_share_prices. In rstudio, create a project within the nse_share_prices. Ensure all the files are in the same file type, be it .xlsx, .xls or .csv and are named in the same format e.g dd-mm-yyyy. Your daily_files folder would look look like this:

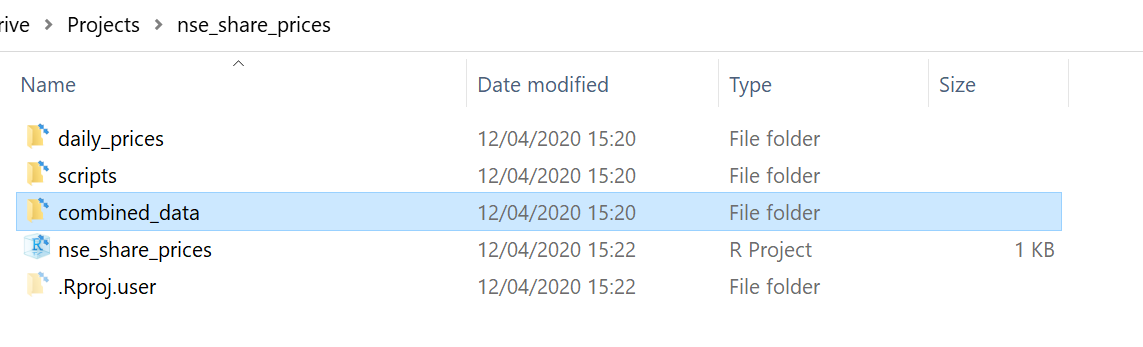
Let’s assume that within your parent folder (nse_share_prices) you have the following folders:
daily_files which contains the share prices files
scripts which contains all the scripts you write pertaining this project
combined_data which will contain the combined dataset we will create
Your project folder will look like this:
Step 2: Create a function to read the files
Within your scripts folder, create .R or .Rmd file to read your data. In this example, the files are named as dates corresponding to share prices so we want to add a date column to each file that takes the name of the file. We will create a function that reads each file, removes a column, creates a date column and populates the date column:
library(readxl)
library(dplyr)
filepath = "../daily_files/"
prepare_daily_files = function(filename){
file = read_excel(paste0(filepath, filename))
filename = gsub(".xlsx", "", filename)
colnames(file) = c("company", "last_traded_price_in_ksh", "previous_price_in_ksh", "change")
file = file %>% select(-change)
file$date = as.Date(filename, format = "%d-%m-%Y")
return(file)
}If your files require more data preparation, you can add code to do that within the prepare_daily_prices function. The file path format will depend on the operating system used. This example uses Windows. In .rmd file, note the use of “../” in filepath to specify the parent directory such that “../daily_files/ indicates sibling directory. In .r file, use”./".
We test the function with one file to confirm that it works by running prepare_daily_files() on a single file:
test_file = prepare_daily_files("09-04-2020.xlsx")Step 3: Create a list of the files you want to read
Once you’re satisfied with your function, list all the relevant files in your daily_prices directory:
daily_files = list.files(filepath, ".xlsx")Step 4: Read all the listed files and combine them into a single dataset
Method 1
My first instinct was to create an empty dataframe, then bind_rows() each file to the resulting dataframe at the end of previous loop like this:
combined_data = data.frame(matrix(ncol = 4, nrow = 0))
colnames(combined_data) = c("company", "last_traded_price_in_ksh", "previous_price_in_ksh", "date")
for (i in 1:length(daily_files)){
filename = daily_files[i]
file = prepare_daily_files(daily_files[i])
combined_data = bind_rows(combined_data, file)
}Note how I have used the same name “combined_data” in the for loop as I used to create the empty dataframe. If you use a different name in the for loop, only data from the last file will be returned.
Method 2
I had used a different name and it took ages to figure out what I was doing wrong and in that process, I came across a different method to combine the data from stackoverflow. Here is a description of this second method:
Start by initialializing a list into which the files will be stored once read, then use a for loop to read the files and assign each file to the created list.
filelist = list()
for (i in 1:length(daily_files)){
filename = daily_files[i]
result_file = prepare_daily_files(daily_files[i])
filelist[[i]] = result_file
}When the above code runs successfully, you will see in your environment object filelist containing the same number of files as your daily_files folder. When you call filelist[[1]], you will be able to see the contents of file 1.
Combine the data in the list as follows:
combined_data = do.call(bind_rows, filelist)combined_data will contain data from all the files read. In case of errors listing the files generating errors, subset the problematic files each at a time to see what is causing the errors. For example, if file 10 is causing an error, use filelist[[10]] to view file 10 and to see possible reasons for the error. From my experience, it could be that the problematic file is different from the other files in a way you had not anticipated when creating prepare_daily_files(). You can rectify the file and try reading the files again.
The prepare_daily_prices function can be modified to accommodate different file types and different data cleaning steps as needed.
Putting everything together
All the code from method 1 looks like this:
library(readxl)
library(dplyr)
filepath = "../daily_files/"
prepare_daily_files = function(filename){
file = read_excel(paste0(filepath, filename))
filename = gsub(".xlsx", "", filename)
colnames(file) = c("company", "last_traded_price_in_ksh", "previous_price_in_ksh", "change")
file = file %>% select(-change)
file$date = as.Date(filename, format = "%d-%m-%Y")
return(file)
}
test_file = prepare_daily_files("09-04-2020.xlsx")
daily_files = list.files(filepath, ".xlsx")
combined_data = data.frame(matrix(ncol = 4, nrow = 0))
colnames(combined_data) = c("company", "last_traded_price_in_ksh", "previous_price_in_ksh", "date")
for (i in 1:length(daily_files)){
filename = daily_files[i]
file = prepare_daily_files(daily_files[i])
combined_data = bind_rows(combined_data, file)
}All the code from method 2 looks like this:
library(readxl)
library(dplyr)
filepath = "../daily_files/"
prepare_daily_files = function(filename){
file = read_excel(paste0(filepath, filename))
filename = gsub(".xlsx", "", filename)
colnames(file) = c("company", "last_traded_price_in_ksh", "previous_price_in_ksh", "change")
file = file %>% select(-change)
file$date = as.Date(filename, format = "%d-%m-%Y")
return(file)
}
test_file = prepare_daily_files("09-04-2020.xlsx")
daily_files = list.files(filepath, ".xlsx")
filelist = list()
for (i in 1:length(daily_files)){
filename = daily_files[i]
result_file = prepare_daily_files(daily_files[i])
filelist[[i]] = result_file
}
combined_data = do.call(bind_rows, filelist)The combined data looks like this:

Step 5: Save the combined data
The point of reading all the files and combining them into a single dataset is to use the data later. To avoid combining the data every single time you need it, you can save it in the combined_data folder in your preferred file type:
write.csv(combined_data, "../combined_data/april_combined_data.csv", row.names = F)Tools:
References: