In the information age, we have access to almost every piece of information imaginable in a matter of seconds. However, at any given moment, we only need very specific and negligible portions. A good example is when we are reading/watching news, we are only interested in particular segments and particular details from those segments. For some it’s sports and within the sports category, some people will pick up information only on football matches whilst others on athletes.
Beyond our individual information consumption patterns, organizations may need to answer particular questions from huge bodies of text. It could be doctors combing through years of research to identify amongst other things: symptoms, experiments, cures and central persons in the management of a given condition. It could be lawyers perusing through collections of precedents. It could be customer service agents identifying their most disgruntled customers from various streams of feedback - emails, social media comments etc. Or it could be us today, figuring out the following:
The topics that dominated local dailies in the past 10 years
Media coverage given to Uhuru, Ruto and Raila in the past 10 years
The public friends and enemies of President Uhuru in the past 10 years
The persons who have been at the center of the corruption nightmare plaguing Kenya
Let’s get started.
Data collection and cleaning
From https://archive.org/web/, we extract daily nation, standard, business daily and star headlines posted on the front pages of each of the aforementioned media outlets. The script to scrape the headlines is here.
The combined and cleaned data looks likes this:
## # A tibble: 6 x 3
## date source headline
## <date> <chr> <chr>
## 1 2008-10-14 business_daily Trade financing drought hits Kenyan companies
## 2 2008-10-14 business_daily House asks Treasury to table fresh budget pla
## 3 2008-10-14 business_daily Kenya gets harsh human rights verdic
## 4 2008-10-14 business_daily Ripple effects of global crisis set to hit East Afr~
## 5 2008-10-14 business_daily Manufacturers cut product sizes to beat recessio
## 6 2008-10-14 business_daily Revenues stagnate at port despite rise in traffi## [1] "Earliest date: 2008-10-14"## [1] "Latest date: 2019-08-29"We have headlines from October 2008 upto August 2019.
Topic Modelling
Topic modelling is the process of identifying the main subjects covered by body/bodies of text. Think of it as summarizing a book by identifying and grouping the recurring words and characters.
A simple LDA topic model reveals three major topics covered by the scraped headlines as shown on the left side of the figure below. The LDA code is here.
Uhuru, market, police, raila, ruto, bank, court and tax are some of the words that dominated the headlines as shown on the right side of the plot below.
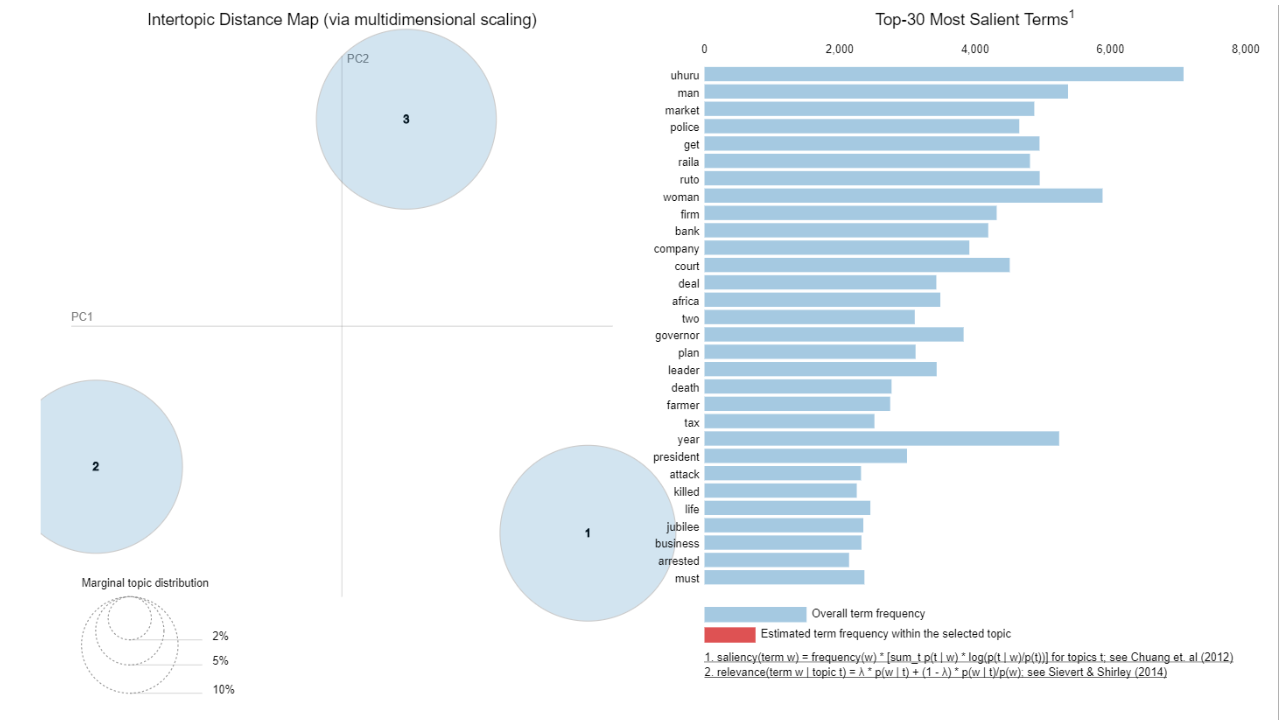
Let’s take a look at the three topics:
Topic 1: Economy and business news
We can call the first topic “Economy and business” as it contains key words such as market, bank, company, firm, deal, tax, price, cash, power and billion. This topic can be attributed mainly to Business Daily headlines.

Topic 2: Crimes
The second topic covers general stories especially crimes as illustrated by words such as death, murder, police, attack and kill.
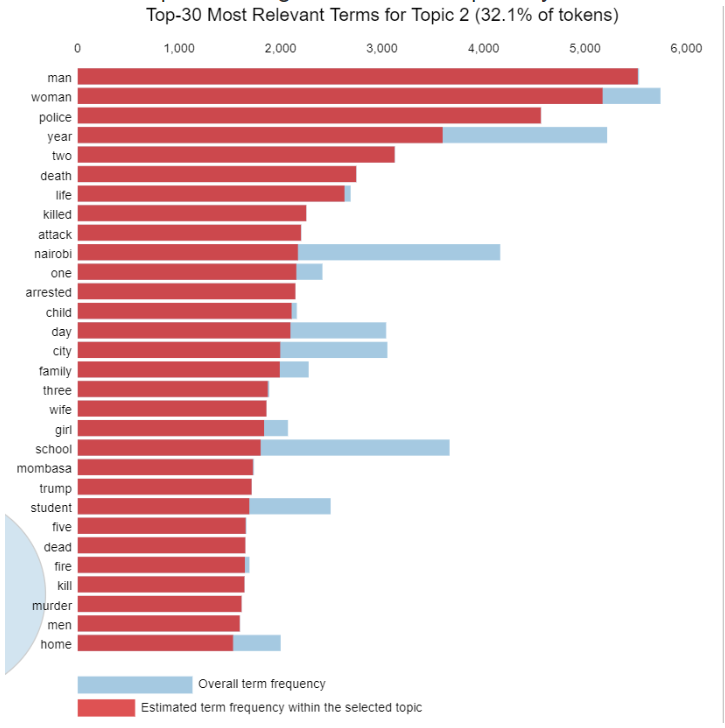
Topic 3: Politics
Topic 3 is dominated by politicians and political organizations such as uhuru, ruto, raila, governors and jubilee party. We also see words such as health, teachers, poll, graft and court that tie political entities to issues that affected the country significantly in the past 10 years.

In the remaining section, we delve deeper into topic 3.
Media coverage of Uhuru, Raila and Ruto
Let’s us explore topic 3 (Politics) a little further. As the top political personalities in the country, Uhuru, Raila and Ruto dominated the headlines. Let us see how the media covered each of the 3 individuals in the past 10 years.
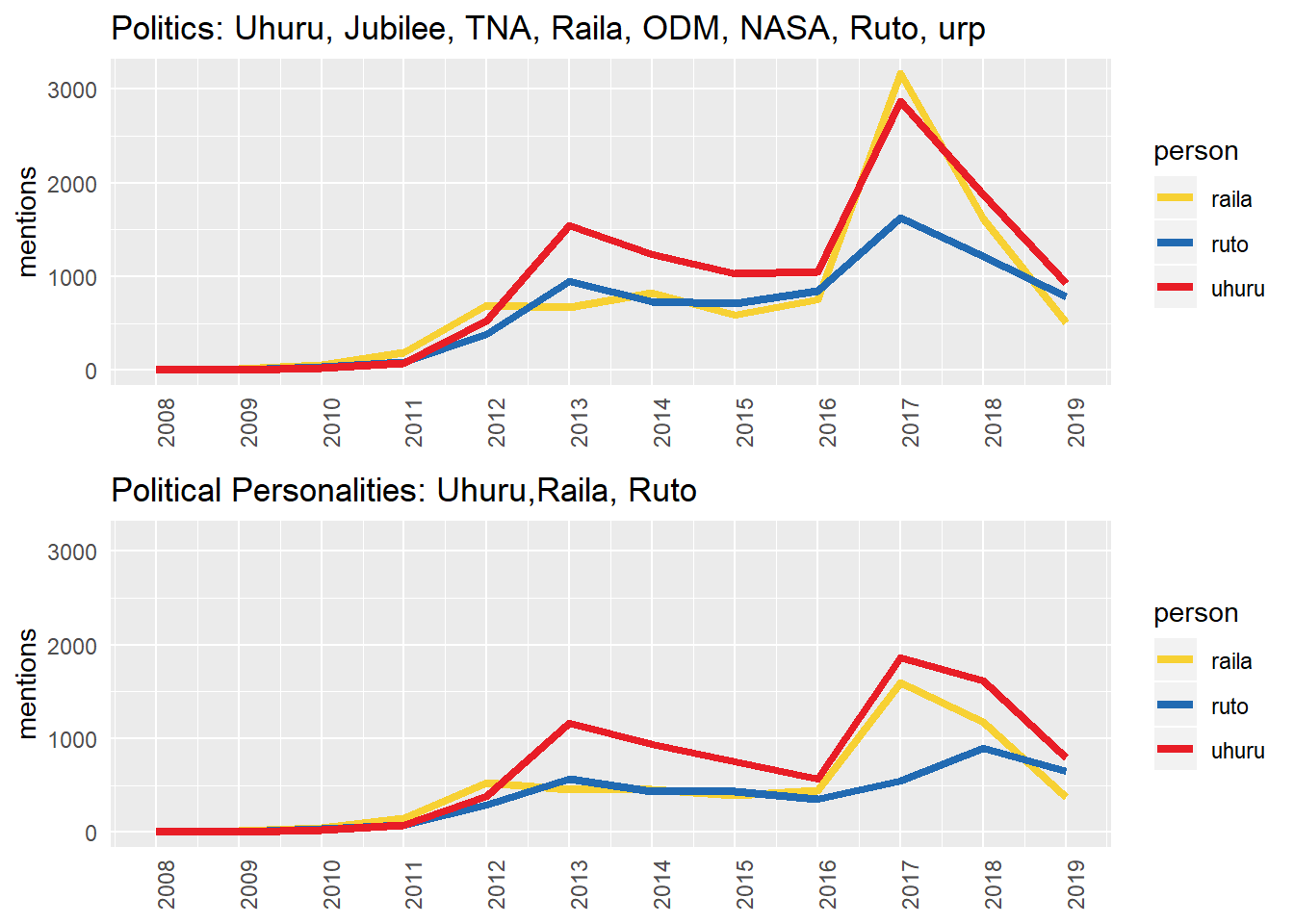
The three politicians started from a fairly level ground in 2008/2009 when Raila Odinga was the prime minister and Uhuru Kenyatta was the finance minister. Around 2011, as the 2013 elections neared, the media increased the coverage of the three with Raila getting more attention. This could be because he held a higher position in the government as the prime minister and he had been in the spotlight earlier during the referendum.
From 2012, Uhuru and Ruto gained more attention from the media due to the coverage of the ICC cases against them.Between 2013 and 2016, Uhuru’s spotlight outshone the others due to his presidential position. In this period, Ruto and Raila were receiving almost equal coverage.
In 2016, as the 2017 elections neared, media coverage of the three spiked peaking in 2017. Notice how when the coverage includes political parties, Raila outshone the others in 2017. After the 2017 elections, the media gradually withdrew its attention from the three.
Towards the end of 2018 and beginning of 2019, Ruto’s media coverage started levelling off as the others’ continued dipping. Let us zoom into the post 2017 election.
The fading star of Raila and growing star of Ruto

Overall, the media coverage on all the three individuals has been declining since January 2018. However, there are two significant observations:
Spike of Raila’s and Uhuru’s coverage in the handshake month of March 2018 with Ruto further away from the limelight
Fading of Rails’s spotlight and growing of Ruto’s spotlight to an extent that Ruto is almost receiving equal coverage as Uhuru from March 2019.
These are just my observations. Depending on the focus of the lens and the story teller’s motivation, different stories could be told from the same data.
Public friends and enemies of Uhuru
We start by subsetting the news dataset to get only the headlines that mention Uhuru. We then use named entity recognition to extract names of persons, organizations and places mentioned alongside Uhuru.
When given this statemet “Michael Jordan meets Uhuru at Kasarani Stadium”, ner identifies Michael Jordan and Uhuru as persons and Kasarani Stadium as a building/related object.

When named entity recognition is applied to our headlines, it generates results as shown below:


As shown above, the results of named entity recognition are far from accurate, but they form a good skeleton for data cleaning. Alongside named entity recognition, there is parts of speech tagging which identifies whether a word is a noun, adjective etc. In the example above, I extracted nouns. The named entity recognition code is here.
After cleaning the results of named entity recognition, we end up with data that looks like this:
## Parsed with column specification:
## cols(
## source = col_character(),
## date = col_date(format = ""),
## headline = col_character(),
## entities = col_character()
## )## # A tibble: 6 x 4
## source date headline entities
## <chr> <date> <chr> <chr>
## 1 daily_nat~ 2008-11-04 Similarities in US election and Kibaki~ usa, kibaki, uh~
## 2 standard 2009-09-18 How vote turned tables on Uhuru, Ruto ~ uhuru, ruto
## 3 standard 2009-09-28 Uhuru to ask for more funds at IMF Wor~ uhuru, imf, wor~
## 4 standard 2010-01-07 Raila ahead of Uhuru in Central Provin~ raila, uhuru, c~
## 5 standard 2010-02-24 Uhuru Signs Japan 3 ... uhuru, japan
## 6 standard 2010-06-03 Raila upstages Uhuru by announcing Sh5~ raila, uhuru, c~We use column entities to create a network graph that shows who were mentioned alongside Uhuru in the headlines and how frequent the mentions were. The mentions range from Uhuru mentioning someone, another person such as Raila mentioning Uhuru, a columnist writing an article about Uhuru etc. The network graph below shows the entities which were most frequently mentioned alongside Uhuru in the headlines.

The corruption web
As we did in the previous section, we can get headlines that mention graft and other related terms such as corruption, steal etc. Thereafter, we can apply named entity recognition on the graft related headlines to identify persons and organizations are mentioned in these headlines.
The cleaned graft-related data looks as follows:
## # A tibble: 6 x 3
## date headline entities
## <date> <chr> <chr>
## 1 2010-02-02 US lauds Kenyan efforts on graft ~ usa
## 2 2010-02-13 Graft: Four PSs on suspension yet~ karega mutahi, romano kiome, al~
## 3 2010-02-20 Kacc to probe fraud corruption in~ eacc, kplc
## 4 2010-04-16 Judiciary hindering anti-graft wa~ judiciary
## 5 2010-06-15 KRA and clearings agents accused ~ kra
## 6 2010-07-03 Kenya anti-graft czar Lumumba tak~ kenya, lumumbaUsing this data, particularly column “entities”, we create a network graph that show the persons and institutions that have been frequently mentioned in graft-related headlines in the past 10 years. The bigger the red dot, the more an entity was mentioned in the graft-related headlines.
 At the center of the graph, we see EACC and Uhuru as the main characters in the Kenyan corruption story alongside Raila and parliament. Here, we do not assess who are the proponents and opponents of corruption. We focus on the characters and not the roles of the characters.
At the center of the graph, we see EACC and Uhuru as the main characters in the Kenyan corruption story alongside Raila and parliament. Here, we do not assess who are the proponents and opponents of corruption. We focus on the characters and not the roles of the characters.
Data source: Wayback Machine
References:
https://towardsdatascience.com/topic-modeling-and-latent-dirichlet-allocation-in-python-9bf156893c24
https://www.machinelearningplus.com/nlp/topic-modeling-gensim-python/
Tools: R, Python, Excel
Data and scripts repository: https://github.com/florencewambui/Kenya-Newspaper-Headlines